.png)
What is a data warehouse anyway?

The business intelligence world breeds plenty of jargon and acronyms. This story is about the core idea of what a data warehouse is, and what the basic methods of construction, and information delivery are.
This article focuses on tangibles: databases, data processes, reports. Things that have real existence in a business intelligence solution. There’s plenty of worthy ideas and concepts to stack on top of that: methodology, metrics, data access policies, roll-out plans, technology and vendor choices among others. I’m not talking about any of those today. If you’re looking at the field of business intelligence from the outside, it looks like a sticky confusing mess. A miasma of methodology, marketing terms and jargon. That’s because it is.
Everyone touting jargon and buzzwords outside a BI conference likely just tries to impress you. Don’t be impressed. The core idea behind a basic data warehouse is simple.
This article explains the basic structure of a business intelligence solution. When you, in your own time, look up the definition of any BI jargon that is thrown your way, the explanation will be likely in terms of the basic structure you’ll see explained in this article.
Why would you want a data warehouse?
Let’s start with the pain point a data warehouse addresses. Successful companies grow and reach a point where it’s impossible to gain consolidated insight into business metrics. The reason is simple. The company runs multiple operational systems: accounting, sales, project management, customer support, ops. Each system is separately owned by a different department, or even outsourced. And each is designed to perform different operational tasks. These systems usually do not share or exchange data. Some systems also do not keep a history of records, focusing on maintaining current state instead.
Sooner or later it becomes somebody’s job to manually query operational systems, and to their best ability prepare a consolidated spreadsheet report. Once it becomes clear that this approach is error-prone and does not scale, companies start looking to automate it: a business intelligence initiative is born.
What does a data warehouse do?
The technical implementation of a business intelligence project does three fundamental things:
- extract data from the various operational systems
- save that data into a single database
- provide a way to conveniently query said data for the purpose of analysis
The database containing the consolidated input from the operational systems is the data warehouse. Acolytes of different methodologies might disagree, claiming that the data warehouse is not a database, but a process, or that it is the structure of the database, not the database itself. If you’re just getting your feet wet in the field, don’t spend much time arguing semantics. In the real world, outside of academic discourse, the central database containing consolidated data is referred to as the data warehouse.
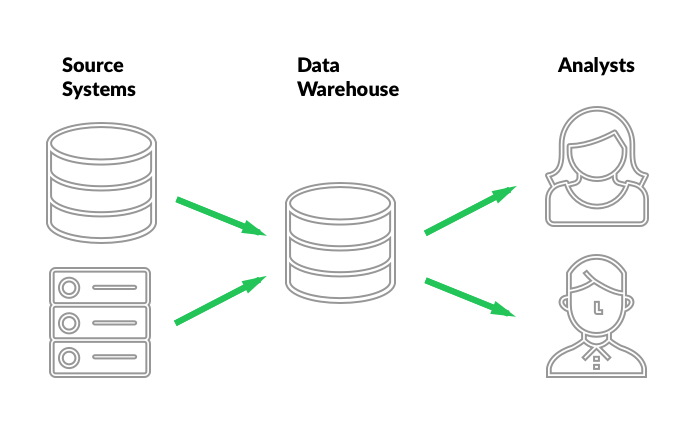
The overwhelming BI jargon stems from differences in implementation and the nature of analysis performed on the resulting data. The details of howdata is extracted, how it is stored, how it is made available for queries, and just how and when the analysis happens gives rise to a plethora of diverse approaches, methodologies and technical solutions. Each approach proposing a unique way of generating value.
How does the data move into the data warehouse?
Data needs to be extracted, transformed into a suitable format, and then loaded into the data warehouse database. Extract, Transform, and Load. ETL. Whatever the technology, tooling or method behind it, ETL refers to a process that moves data around, potentially altering its format or content in-flight. A more general term is data integration. The methodology used for building your data warehouse is going to prescribe a data model. The ETL process transforms source data to fit that model.
It all starts by collecting things in one place
Let’s zoom in on the beginning of the process: data extraction. It turns out that accessing operational data sources is hard. No overwhelming technical difficulty, really. But go ask for full read access on an production database. The answer is ‘no’ with three exclamation marks, before you’ve even finished your request. And for good reasons. Security, compliance, data privacy, performance impact of extraction, all that and more will all be part of the discussion.
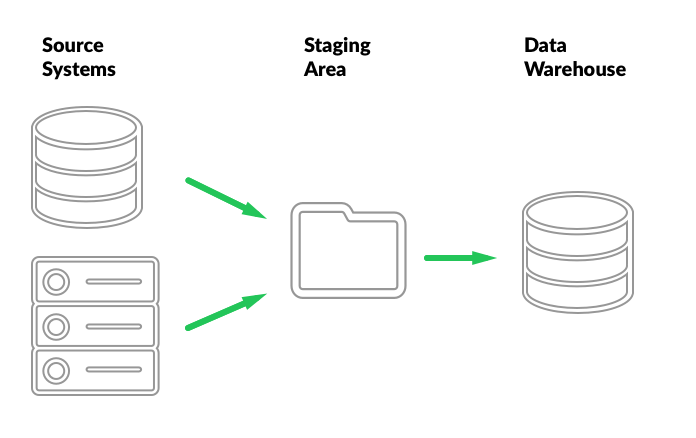
In the end it’s likely that the owner of the source system agrees to schedule some sort of data dump for the BI process to pick up at a secure location. Most of the time data extraction is performed by the owner of the system, and the ETL starts by reading the exported data.
It stands to reason that all source data exported for a particular load cycle should be collected in one place, and possibly archived after the data warehouse is loaded. That place is called the staging area.
Giving users the information they need
Let’s zoom in on the end of the process, where the value of the data warehouse is realized. The data warehouse’s primary function is to historize and store data accurately. There are plenty of ways to go about it. Debates about the merits and evolution of methodologies are anything but idle. One thing there is broad consensus on, is that no matter how you structure it, a data warehouse good at storing historized data correctly and efficiently is either difficult to maintain or difficult to query correctly. As a result, a common approach is to build a data warehouse that is correct, efficient, and relatively straightforward to load, but not trivial to query. The data warehouse is then supplemented by a set of independent, easy-to-query databases that are extracted from it. These databases are called data marts. They are often qualified as disposable data marts, because their entire content can be generated from information stored in the data warehouse at any time.
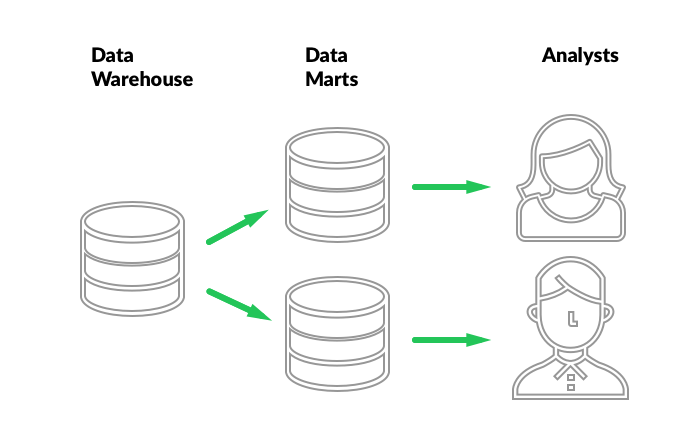
Data marts have several key properties that make them attractive:
- The ETL to build and maintain a data mart is an order of magnitude simpler than the ETL to load the data warehouse. Data marts are easily created, changed, and discarded as analysis requirements change.
- Data marts can expose simple, focused views suitable for specific use cases without overburdening their users with complexity inherent in a complete data warehouse data model.
- Data marts can be built to satisfy technical requirements of reporting and analysis tools. Users are free to choose reporting tools that best suit their needs without introducing vendor-dependent complexity into the data warehouse.
- Data marts can use technology different from the technology of the data warehouse. While a data warehouse is often best maintained in a traditional relational database, data marts often benefit from a column store database. Column store databases are particularly effective at running analytical queries. Analytical queries that take minutes or hours on a relational database often finish virtually instantly or within seconds on a column store. The trade-off is that column stores are particularly slow, or outright incapable of, retrieving or updating individual records, but that is not the primary function of a data mart.
Connecting analytics tools
At the end of the process, analytics tools connect to data marts, allowing users to interact with the data.
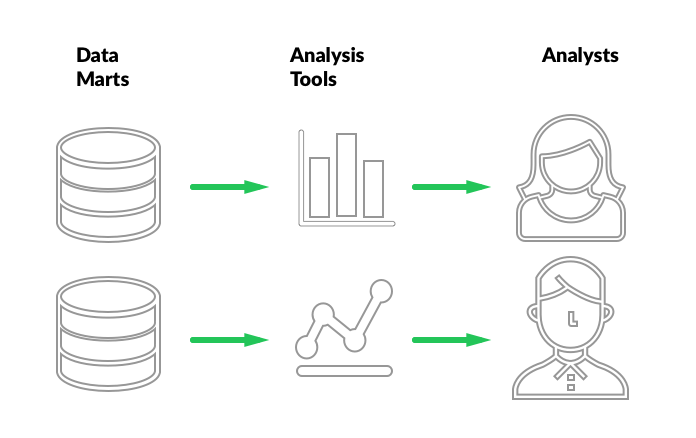
There are plenty of analytics tools out there. Some generate reports, some are good at dashboards, some are running prepared queries, some are interactive and support data exploration, some are browser-based, some are desktop-based. The sky is the limit and your use-case and budget determine your choices here.
Vendors of analytics tools often assume you’ve built a data warehouse and data marts already. In their marketing they’ll tell you that their tool makes all the difference for your BI success, and as far as that relates to end-user experience, roll-out, and adaption, they may well be right. But do not believe that these tools generate much value outside of that. They don’t build a data warehouse for you.
The value inherent in your data warehouse is not created by these tools, it’s merely exposed by them. If the information in your data warehouse is not useful, no amount of silver-lining or interactivity an analytics tool adds can compensate for that fact. The value of a data warehouse is in the correctness, completeness, consistency, and accessibility of the information therein. That value is determined by the quality of the data your source systems keep, and the ability of your data warehouse to correlate data from different systems. The reporting tools deliver this value to your teams. Nothing more, nothing less.
Conclusion
If you’re thinking about building a business intelligence solution for your company, I’d recommend sticking to the basic structure. There’s plenty of details to get wrong when doing it for the first time, so it’s advisable to make sure at least one team member has solid BI background. Technology choices, methodology, implementation details, and communication can each make or break a successful BI initiative.
Do not waste much time chasing the buzzwords of the week. What to expect from your BI initiative is going to depend mostly on the quality of the data you have, how your roll it out to your teams, and how you act on what you learn from it. The methodology and vendor choices are going to make a difference in cost of ownership, ability to adapt to change, and ability to include and correlate new data sources.
By Slawomir Chodnicki
Source https://blog.twineworks.com/what-is-a-data-warehouse-anyway-3c5af58dd27e




No comments:
Post a Comment